















Amazon S3 and HTML5 URLs
Some time ago we came across the need to use HTML5 mode for URLs for an Angular 1.x app, instead of the default hashbang (#!) URL scheme. Changing this was a bit challenging by the way this impacts both backend and frontend, but it was also quite interesting since it even has an historic component to it.
Different behaviors
One thing to keep in mind, is that browsers will treat the hash ’#’ as a special character and will not include it nor everything after it in requests to the server. Also, unlike any other change in the URL, changes after the # character will not trigger a new request. Historically, this was used to navigate to a precise point in a web page, so for instance this link https://docs.djangoproject.com/en/1.10/ref/models/querysets/#get-or-create takes you to the specific documentation for Django’s get_or_create method.
SPA and reloads
One of the strongholds of Single Page Apps is that they allow the user to have a seamless experience between pages, avoiding a whole reload when changing sections. But since it’s quite convenient to have URLs for some features (such as the back button) and sharing them, web frameworks used the hash bang (#!) URL format to have the benefits without having to reload the page. So, we will have something like https://mymusiccatalogueapp.com/#!/discs/ or https://mymusiccatalogueapp.com/#!/artists/ and https://mymusiccatalogueapp.com/#!/artists/foo-fighters/profile/.
This caused a huge fizz some time ago, and at http://www.fakingfantastic.com/2011/02/09/using-hash-bangs-in-your-urls/ you can see a great reply to a great article about URL structure, which does give some historic insight.
What HTML5 brought along
The HTML 5 specification introduced the History API, which allows an application to listen, intercept and make changes in the browser history and URL changes. With this, web frameworks can use traditional URLs and skip the page reload. While we navigate through our SPA we will see changes in the URL before the # character that will not trigger a reload.
First access
All of this seems to work just fine, but there is a small problem in the first page load. If your URL is now https://mymusiccatalogueapp.com/artists/foo-fighters/profile/, this will send the whole URL with your HTTP request. Problem is that there is no such/artists/foo-fighters/profile/ resource in the server, it’s just state information for the frontend app. This will then return a 404 Not Found error.
If your content is served with a web server like NGINX, the solution is quite easy and you just need to use the try_files directive in your config. If the resource requested is available, return it. Else, return the index.html page with a nice 200 OK status code so the app will load and go to the desired content.
But when the application is deployed in a S3 bucket, we cannot do this. That is, because although we can customize the error page so the index.html is always returned, we can’t customize the response code. So a 404 is returned which will send crawlers away and make browsers feel dizzy.
This helpful answer at stackoverflow explains a very elegant and simple solution for this problem using CloudFront from AWS. So instead of directly serving our SPA through S3, we will configure a CloudFront instance with our S3 bucket as the only origin and customize the behaviour for 404 errors pages. We want to return /index.html for both 404 and 403 errors, with a custom 200 OK status code.
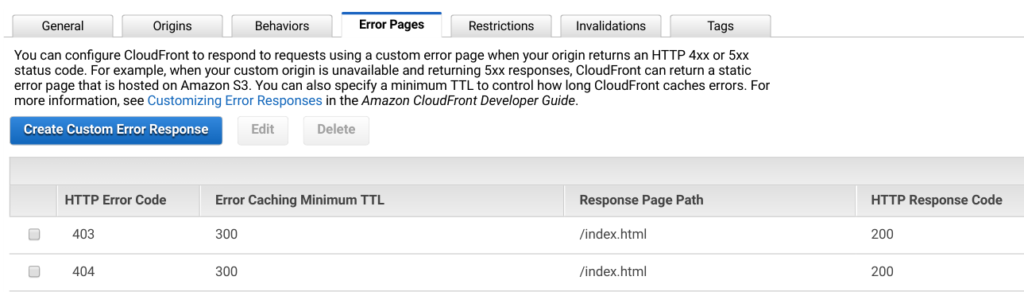
You then switch your domain to the CloudFront instance instead of your S3 bucket and you are all set to start delivering your SPA without hashbang URLs.
See related posts

Automated Testing Applied
Let’s explore how automated testing has made developers’ work more efficient and diverse.

Learn About Web Accessibility
Web accessibility is an essential pillar in developing and designing websites and applications that everyone can use.

